在瀏覽器輸入 URL 回車之後發生了什麼(超詳細版)
本文轉自4ark
這個問題已經是老生常談了,更是經常被作為面試的壓軸題出現,網上也有很多文章,但最近閒的無聊,然後就自己做了一篇筆記,感覺比之前理解更透徹了。
前言
這個問題已經是老生常談了,更是經常被作為面試的壓軸題出現,網上也有很多文章,但最近閒的無聊,然後就自己做了一篇筆記,感覺比之前理解更透徹了。
這篇筆記是我這兩天看了數十篇文章總結出來的,所以相對全面一點,但由於我是做前端的,所以會比較重點分析瀏覽器渲染頁面那一部分,至於其他部分我會羅列出關鍵詞,感興趣的可以自行查閲,
注意: 本文的步驟是建立在,請求的是一個簡單的 HTTP 請求,沒有 HTTPS、HTTP2、最簡單的 DNS、沒有代理、並且服務器沒有任何問題的基礎上,儘管這是不切實際的。
大致流程
- URL 解析
- DNS 查詢
- TCP 連接
- 處理請求
- 接受響應
- 渲染頁面
URL 解析
地址解析:
首先判斷你輸入的是一個合法的 URL 還是一個待搜索的關鍵詞,並且根據你輸入的內容進行自動完成、字符編碼等操作。
HSTS
由於安全隱患,會使用 HSTS 強制客户端使用 HTTPS 訪問頁面。詳見:你所不知道的 HSTS。
其他操作
瀏覽器還會進行一些額外的操作,比如安全檢查、訪問限制(之前國產瀏覽器限制 996.icu)。
檢查緩存
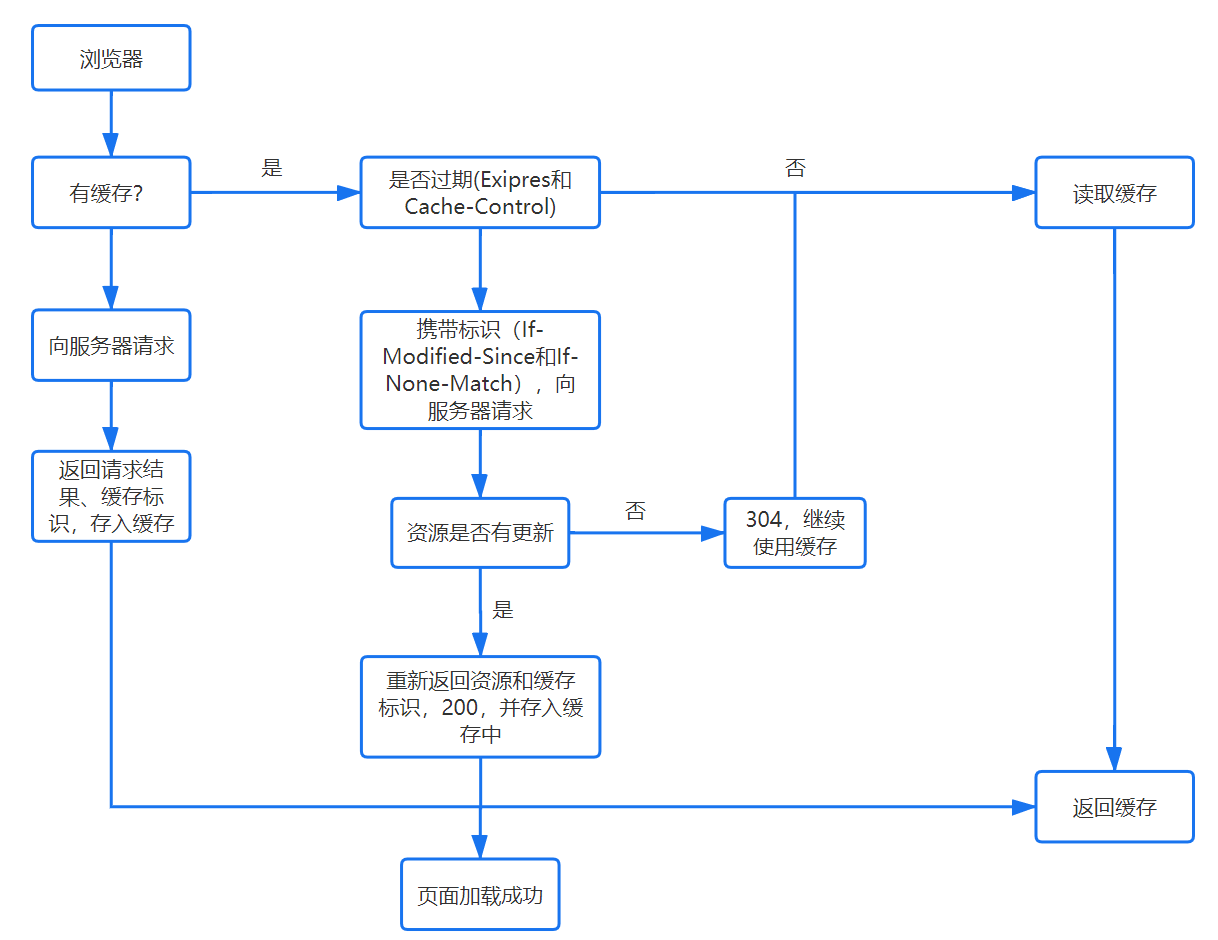
DNS 查詢
基本步驟

瀏覽器緩存
瀏覽器會先檢查是否在緩存中,沒有則調用系統庫函數進行查詢。
操作系統緩存
操作系統也有自己的 DNS 緩存,但在這之前,會向檢查域名是否存在本地的 Hosts 文件裏,沒有則向 DNS 服務器發送查詢請求。
路由器緩存
路由器也有自己的緩存。
ISP DNS 緩存
ISP DNS 就是在客户端電腦上設置的首選 DNS 服務器,它們在大多數情況下都會有緩存。
根域名服務器查詢
在前面所有步驟沒有緩存的情況下,本地 DNS 服務器會將請求轉發到互聯網上的根域,下面這個圖很好的詮釋了整個流程:
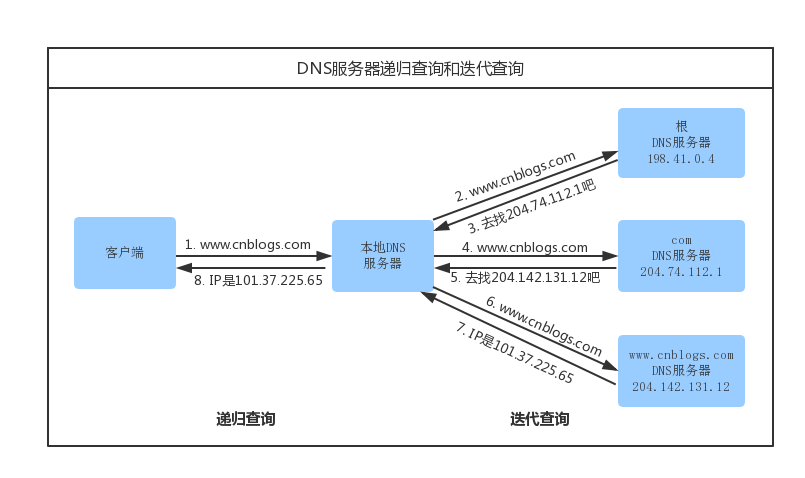
根域名服務器:維基百科
需要注意的點
- 遞歸方式:一路查下去中間不返回,得到最終結果才返回信息(瀏覽器到本地 DNS 服務器的過程)
- 迭代方式,就是本地 DNS 服務器到根域名服務器查詢的方式。
- 什麼是 DNS 劫持
- 前端 dns-prefetch 優化
TCP 連接
TCP/IP 分為四層,在發送數據時,每層都要對數據進行封裝:
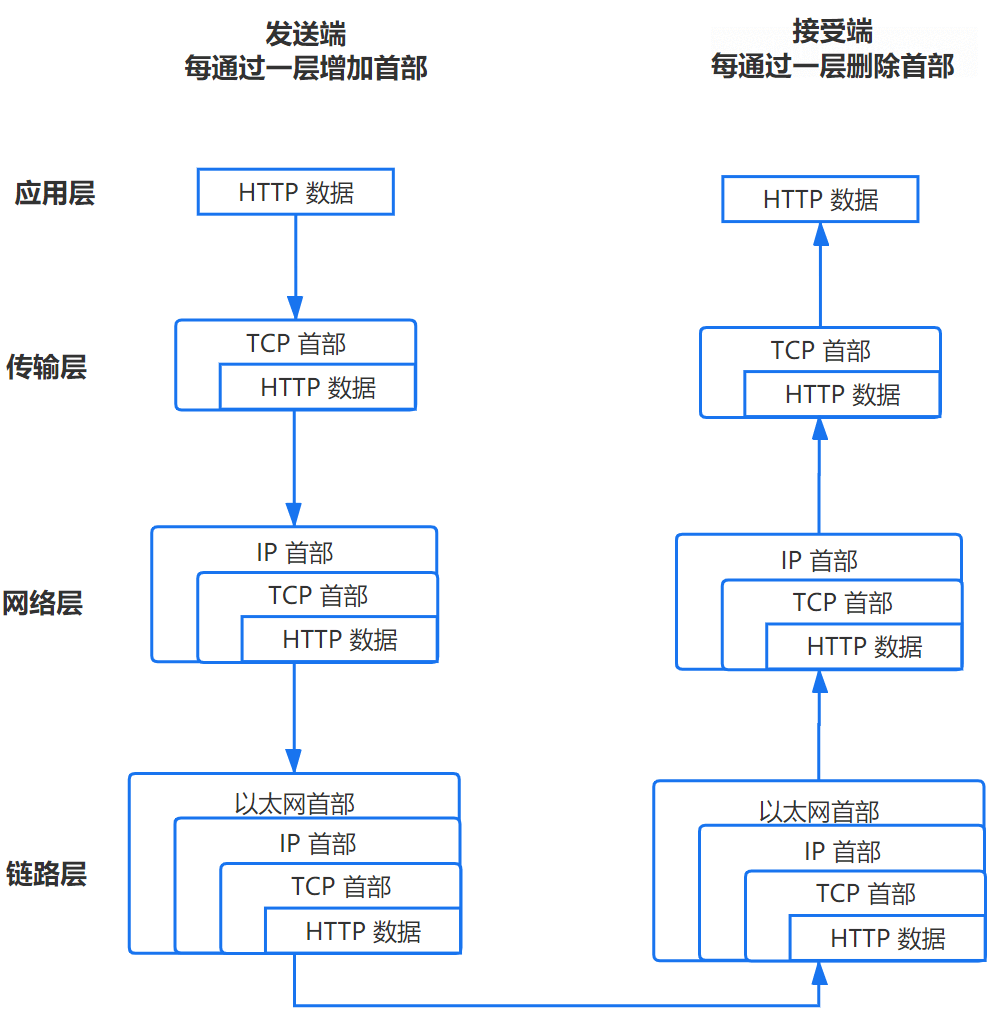
1. 應用層:發送 HTTP 請求
在前面的步驟我們已經得到服務器的 IP 地址,瀏覽器會開始構造一個 HTTP 報文,其中包括:
- 請求報頭(Request Header):請求方法、目標地址、遵循的協議等等
- 請求主體(其他參數)
其中需要注意的點:
- 瀏覽器只能發送 GET、POST 方法,而打開網頁使用的是 GET 方法
2. 傳輸層:TCP 傳輸報文
傳輸層會發起一條到達服務器的 TCP 連接,為了方便傳輸,會對數據進行分割(以報文段為單位),並標記編號,方便服務器接受時能夠準確地還原報文信息。
在建立連接前,會先進行 TCP 三次握手。
關於 TCP/IP 三次握手,網上已經有很多段子和圖片生動地描述了。
相關知識點:
- SYN 泛洪攻擊
3. 網絡層:IP 協議查詢 Mac 地址
將數據段打包,並加入源及目標的 IP 地址,並且負責尋找傳輸路線。
判斷目標地址是否與當前地址處於同一網絡中,是的話直接根據 Mac 地址發送,否則使用路由表查找下一跳地址,以及使用 ARP 協議查詢它的 Mac 地址。
注意:在 OSI 參考模型中 ARP 協議位於鏈路層,但在 TCP/IP 中,它位於網絡層。
4. 鏈路層:以太網協議
以太網協議
根據以太網協議將數據分為以 “幀” 為單位的數據包,每一幀分為兩個部分:
- 標頭:數據包的發送者、接受者、數據類型
- 數據:數據包具體內容
Mac 地址
以太網規定了連入網絡的所有設備都必須具備 “網卡” 接口,數據包都是從一塊網卡傳遞到另一塊網卡,網卡的地址就是 Mac 地址。每一個 Mac 地址都是獨一無二的,具備了一對一的能力。
廣播
發送數據的方法很原始,直接把數據通過 ARP 協議,向本網絡的所有機器發送,接收方根據標頭信息與自身 Mac 地址比較,一致就接受,否則丟棄。
注意:接收方迴應是單播。
相關知識點:
- ARP 攻擊
服務器接受請求
接受過程就是把以上步驟逆轉過來,參見上圖。
服務器處理請求
大致流程

HTTPD
最常見的 HTTPD 有 Linux 上常用的 Apache 和 Nginx,以及 Windows 上的 IIS。
它會監聽得到的請求,然後開啟一個子進程去處理這個請求。
處理請求
接受 TCP 報文後,會對連接進行處理,對 HTTP 協議進行解析(請求方法、域名、路徑等),並且進行一些驗證:
- 驗證是否配置虛擬主機
- 驗證虛擬主機是否接受此方法
- 驗證該用户可以使用該方法(根據 IP 地址、身份信息等)
重定向
假如服務器配置了 HTTP 重定向,就會返回一個 301永久重定向響應,瀏覽器就會根據響應,重新發送 HTTP 請求(重新執行上面的過程)。
關於更多:詳見這篇文章
URL 重寫
然後會查看 URL 重寫規則,如果請求的文件是真實存在的,比如圖片、html、css、js 文件等,則會直接把這個文件返回。
否則服務器會按照規則把請求重寫到 一個 REST 風格的 URL 上。
然後根據動態語言的腳本,來決定調用什麼類型的動態文件解釋器來處理這個請求。
以 PHP 語言的 MVC 框架舉例,它首先會初始化一些環境的參數,根據 URL 由上到下地去匹配路由,然後讓路由所定義的方法去處理請求。
瀏覽器接受響應
瀏覽器接收到來自服務器的響應資源後,會對資源進行分析。
首先查看 Response header,根據不同狀態碼做不同的事(比如上面提到的重定向)。
如果響應資源進行了壓縮(比如 gzip),還需要進行解壓。
然後,對響應資源做緩存。
接下來,根據響應資源裏的 MIME 類型去解析響應內容(比如 HTML、Image 各有不同的解析方式)。
渲染頁面
瀏覽器內核

不同的瀏覽器內核,渲染過程也不完全相同,但大致流程都差不多。
基本流程
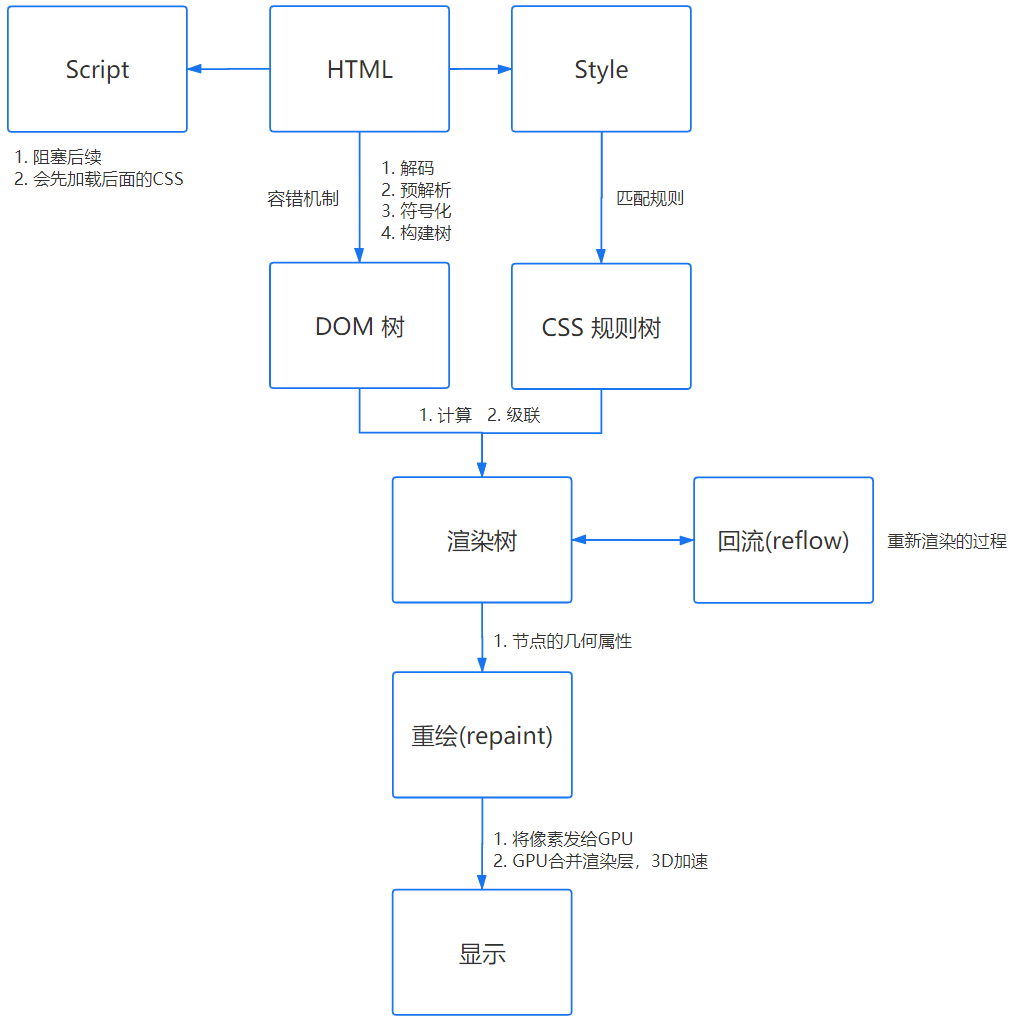
HTML 解析
首先要知道瀏覽器解析是從上往下一行一行地解析的。
解析的過程可以分為四個步驟:
1. 解碼(encoding)
傳輸回來的其實都是一些二進制字節數據,瀏覽器需要根據文件指定編碼(例如 UTF-8)轉換成字符串,也就是 HTML 代碼。
2. 預解析(pre-parsing)
預解析做的事情是提前加載資源,減少處理時間,它會識別一些會請求資源的屬性,比如img標籤的src屬性,並將這個請求加到請求隊列中。
3. 符號化(Tokenization)
符號化是詞法分析的過程,將輸入解析成符號,HTML 符號包括,開始標籤、結束標籤、屬性名和屬性值。
它通過一個狀態機去識別符號的狀態,比如遇到<,>狀態都會產生變化。
4. 構建樹(tree construction)
注意:符號化和構建樹是並行操作的,也就是説只要解析到一個開始標籤,就會創建一個 DOM 節點。
在上一步符號化中,解析器獲得這些標記,然後以合適的方法創建DOM對象並把這些符號插入到DOM對象中。
1 | <html> |
瀏覽器容錯進制
你從來沒有在瀏覽器看過類似” 語法無效” 的錯誤,這是因為瀏覽器去糾正錯誤的語法,然後繼續工作。
事件
當整個解析的過程完成以後,瀏覽器會通過DOMContentLoaded事件來通知DOM解析完成。
CSS 解析
一旦瀏覽器下載了 CSS,CSS 解析器就會處理它遇到的任何 CSS,根據語法規範解析出所有的 CSS 並進行標記化,然後我們得到一個規則表。
CSS 匹配規則
在匹配一個節點對應的 CSS 規則時,是按照從右到左的順序的,例如:div p { font-size :14px }會先尋找所有的p標籤然後判斷它的父元素是否為div。
所以我們寫 CSS 時,儘量用 id 和 class,千萬不要過度層疊。
渲染樹
其實這就是一個 DOM 樹和 CSS 規則樹合併的過程。
注意:渲染樹會忽略那些不需要渲染的節點,比如設置了
display:none的節點。
計算
通過計算讓任何尺寸值都減少到三個可能之一:auto、百分比、px,比如把rem轉化為px。
級聯
瀏覽器需要一種方法來確定哪些樣式才真正需要應用到對應元素,所以它使用一個叫做specificity的公式,這個公式會通過:
- 標籤名、class、id
- 是否內聯樣式
!important
然後得出一個權重值,取最高的那個。
渲染阻塞
當遇到一個script標籤時,DOM 構建會被暫停,直至腳本完成執行,然後繼續構建 DOM 樹。
但如果 JS 依賴 CSS 樣式,而它還沒有被下載和構建時,瀏覽器就會延遲腳本執行,直至 CSS Rules 被構建。
所有我們知道:
- CSS 會阻塞 JS 執行
- JS 會阻塞後面的 DOM 解析
為了避免這種情況,應該以下原則:
- CSS 資源排在 JavaScript 資源前面
- JS 放在 HTML 最底部,也就是
</body>前
另外,如果要改變阻塞模式,可以使用 defer 與 async,詳見:這篇文章
佈局與繪製
確定渲染樹種所有節點的幾何屬性,比如:位置、大小等等,最後輸入一個盒子模型,它能精準地捕獲到每個元素在屏幕內的準確位置與大小。
然後遍歷渲染樹,調用渲染器的 paint() 方法在屏幕上顯示其內容。
合併渲染層
把以上繪製的所有圖片合併,最終輸出一張圖片。
迴流與重繪
迴流 (reflow)
當瀏覽器發現某個部分發現變化影響了佈局時,需要倒回去重新渲染,會從html標籤開始遞歸往下,重新計算位置和大小。
reflow 基本是無法避免的,因為當你滑動一下鼠標、resize 窗口,頁面就會產生變化。
重繪 (repaint)
改變了某個元素的背景色、文字顏色等等不會影響周圍元素的位置變化時,就會發生重繪。
每次重繪後,瀏覽器還需要合併渲染層並輸出到屏幕上。
迴流的成本要比重繪高很多,所以我們應該儘量避免產生迴流。
比如:
display:none會觸發迴流,而visibility:hidden只會觸發重繪。
JavaScript 編譯執行
大致流程
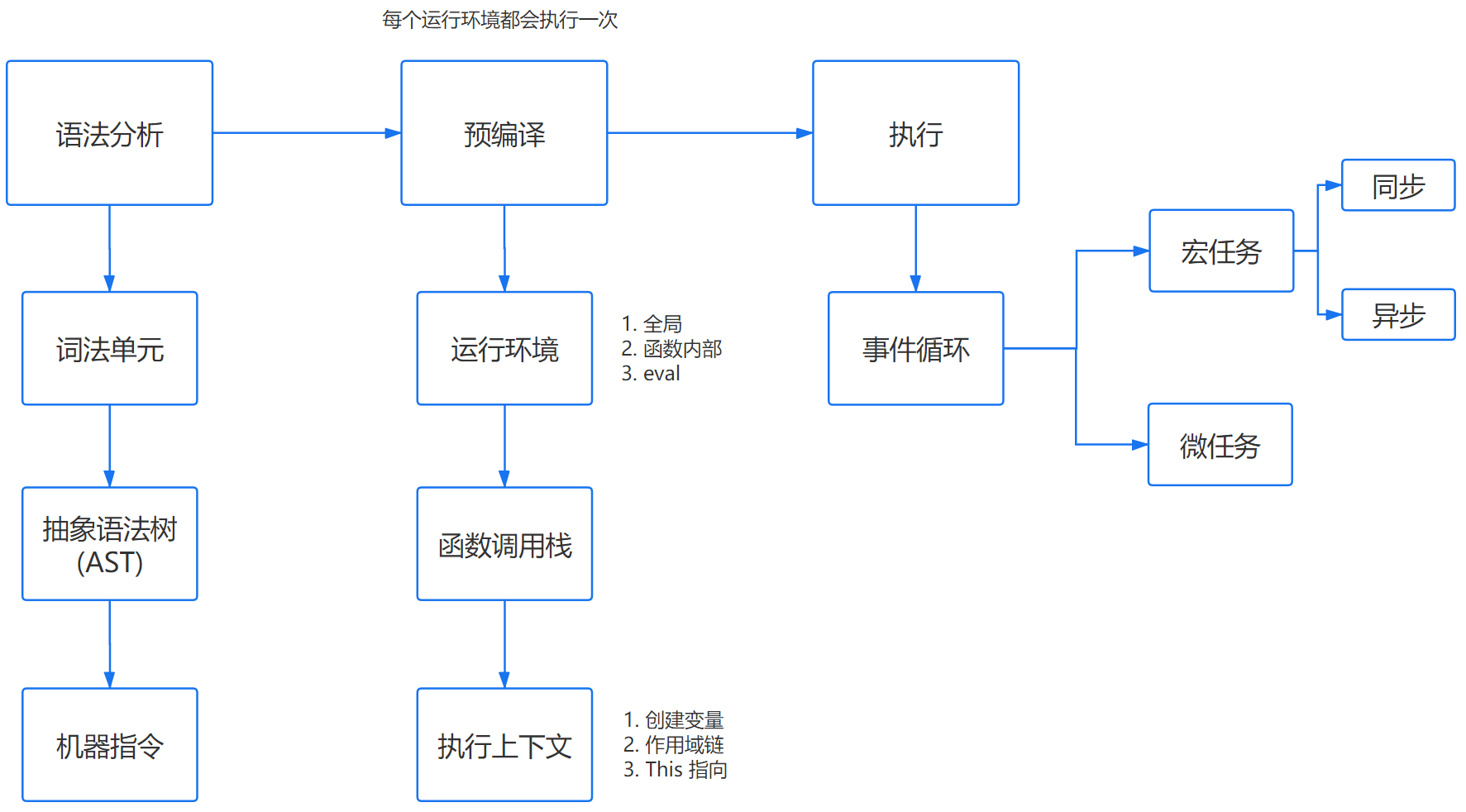
可以分為三個階段:
詞法分析
JS 腳本加載完畢後,會首先進入語法分析階段,它首先會分析代碼塊的語法是否正確,不正確則拋出 “語法錯誤”,停止執行。
幾個步驟:
- 分詞,例如將
var a = 2,,分成var、a、=、2這樣的詞法單元。 - 解析,將詞法單元轉換成抽象語法樹(AST)。
- 代碼生成,將抽象語法樹轉換成機器指令。
預編譯
JS 有三種運行環境:
- 全局環境
- 函數環境
- eval
每進入一個不同的運行環境都會創建一個對應的執行上下文,根據不同的上下文環境,形成一個函數調用棧,棧底永遠是全局執行上下文,棧頂則永遠是當前執行上下文。
創建執行上下文
創建執行上下文的過程中,主要做了以下三件事:
- 創建變量對象
- 參數、函數、變量
- 建立作用域鏈
- 確認當前執行環境是否能訪問變量
- 確定 This 指向
執行
JS 線程

雖然 JS 是單線程的,但實際上參與工作的線程一共有四個:
其中三個只是協助,只有 JS 引擎線程是真正執行的
- JS 引擎線程:也叫 JS 內核,負責解析執行 JS 腳本程序的主線程,例如 V8 引擎
- 事件觸發線程:屬於瀏覽器內核線程,主要用於控制事件,例如鼠標、鍵盤等,當事件被觸發時,就會把事件的處理函數推進事件隊列,等待 JS 引擎線程執行
- 定時器觸發線程:主要控制
setInterval和setTimeout,用來計時,計時完畢後,則把定時器的處理函數推進事件隊列中,等待 JS 引擎線程。 - HTTP 異步請求線程:通過 XMLHttpRequest 連接後,通過瀏覽器新開的一個線程,監控 readyState 狀態變更時,如果設置了該狀態的回調函數,則將該狀態的處理函數推進事件隊列中,等待 JS 引擎線程執行。
注:瀏覽器對同一域名的併發連接數是有限的,通常為 6 個。
宏任務
分為:
- 同步任務:按照順序執行,只有前一個任務完成後,才能執行後一個任務
- 異步任務:不直接執行,只有滿足觸發條件時,相關的線程將該異步任務推進任務隊列中,等待 JS 引擎主線程上的任務執行完畢時才開始執行,例如異步 Ajax、DOM 事件,setTimeout 等。
微任務
微任務是 ES6 和 Node 環境下的,主要 API 有:Promise,process.nextTick。
微任務的執行在宏任務的同步任務之後,在異步任務之前。

代碼例子
1 | console.log('1'); // 宏任務 同步 |
以上代碼輸出順序為:1,3,5,4,2
參考文檔
 Wechat
Wechat- Alipay
- Stripe